
Modélisation d'un arbre avec Django et PostgreSQL (FR)
mar. 27 novembre 2018 Dan Lousqui
Au cas où vous ne le saviez déjà pas, Seald permet de chiffrer des documents. L'une utilisation classique de l'application est de chiffrer un fichier dans un répertoire partagé. Cependant, une fois chiffré, si un utilisateur a besoin de transférer le fichier à une nouvelle personne, elle risque de le déchiffrer et d'envoyer le fichier initialement protégé de façon non sécurisée. C'est pour cela que nous avons développé une nouvelle fonctionnalité : la possibilité de transférer un document chiffré.
(TLDR: Si ce qui vous intéresse est directement le modèle choisi pour implémenter un arbre avec l'ORM Django et une base de données Postgres, directement aller au Résultat)
Cela pose pas mal de problématiques, notamment, qui a le droit d'avoir accès aux événements journalisés et qui a le droit de révoquer l'accès à un fichier ? Pour répondre à cela, nous avons mis en place un système d'arborescence, où un utilisateur à tous les droits sur ses enfants.
Par exemple, si Alice chiffre un fichier pour Bob et Charly, et que Charly le transfert Dylan, alors :
Aliceaura tous les droits sur tout le monde ;Bobn'aura de droits sur personne ;Charlyaura des droits uniquement surDylan;Dylann'aura de droits sur personne.
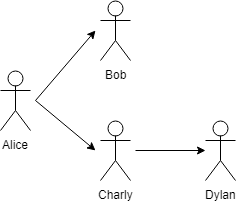
Il s'agit d'un modèle d'arbre. Le but de cet article sera de montrer les choix d'implémentation que nous avons eu pour réaliser cela avec Python et PostgreSQL via l'ORM de Django.
Base et contexte
De base, un document chiffré avec Seald est représenté dans la base de données avec le modèle Django suivant :
class Document(model.Model):
id = models.UUIDField(primary_key=True, default=uuid.uuid4)
owner = models.ForeignKey("SealdUser", on_delete=models.CASCADE)
created = models.DateTimeField(auto_now_add=True)
Nous voulons créer un nouveau modèle, tel que pour chaque destinataire d'un message, l'instance de ce modèle existe, permettant de savoir sur qui le destinataire à des droits, et qui a des droits sur lui :
class DocumentAccessRight(model.Model):
user = models.ForeignKey("SealdUser", on_delete=models.CASCADE)
document = models.ForeignKey("Document", on_delete=models.CASCADE)
# Todo: Ajouter des champs
def get_children(self):
# Todo: implémenter
raise NotImplementedError
def get_parents(self):
# Todo: implémenter
raise NotImplementedError
Ainsi, pour reprendre l'exemple précédent, si Alice veut révoquer un accès à Bob, il suffit de vérifier que Alice
soit parent de Bob dans l'arborescence des DocumentAccessRight.
Maintenant... comment implémenter cela ?
Approche simpliste
Une première façon de faire, assez naïve, est simplement d'ajouter un champ parent à la classe, qui ferait le lien
entre les enfants et les parents :
from django.db import models
class DocumentAccessRight(model.Model):
user = models.ForeignKey("SealdUser", on_delete=models.CASCADE)
document = models.ForeignKey("Document", on_delete=models.CASCADE)
parent = models.ForeignKey(
"DocumentAccessRight",
on_delete=models.CASCADE,
related_name="first_children",
null=True
)
On peut prendre pour convention que le parent d'un owner d'un document est None. Ainsi, l'implémentation des
fonctions peut être la suivante:
from django.db import models
class DocumentAccessRight(model.Model):
...
def get_children(self):
all_children = []
for first_child in self.first_children.all():
all_children.append(first_child)
all_children.extend(first_child.get_children())
return all_children
def get_parents(self):
parents = []
current_parent=self.parent
while current_parent is not None:
parents.append(current_parent)
current_parent = current_parent.parent
raise NotImplementedError
Cette implémentation est la première à laquelle on pense. Elle a le mérite de fonctionner et d'être très faible en stockage (uniquement l'id du parent dans un enfant).
Cependant, il y a un seul soucis : on ne stocke que les enfants directs ou le parent direct en base de données, et le lanqage SQL ne permet pas d'écrire des requêtes récursives.
Ainsi, dans notre exemple entre Alice, Bob, Charly et Dylan, pour récupérer les parents de Dylan, il faudra
exécuter quatre requêtes SQL (une pour chaque noeud). Bien sûr, ces requêtes sont automatiquement exécutées par l'ORM,
mais imaginons un cas avec de nombreux destinataires (à l'échelle d'une entreprise par exemple), la solution n'est
clairement pas viable.
De même, pour récupérer les parents d'un utilisateur, il faudra autant de requête qu'il y a de parent.
Approche vue ailleurs
De façon plus intelligente, certains bibliothèques Django implémentent un modèle d'arbre. Pour cela, elles ajoutent
un champ path représentant le chemin (un peu à la façon d'un fichier sur son filesystem) à partir des parents.
Ainsi, les recherches de hiérarchie s'effectuent de la façon suivante :
- La recherche des parents est triviale : c'est les éléments du chemin ;
- La recherche des enfants est également simple : il suffit de rechercher tous les éléments donc le chemin contient
son identifiant (l'élément au chemin
/foo/bar/bazest forcément un enfant de/foo/et de/bar/).
On peut donc implémenter cette approche de la façon suivante:
from django.db import models
class DocumentAccessRight(model.Model):
user = models.ForeignKey("SealdUser", on_delete=models.CASCADE)
document = models.ForeignKey("Document", on_delete=models.CASCADE)
parent = models.ForeignKey(
"DocumentAccessRight",
on_delete=models.CASCADE,
related_name="first_children",
null=True
)
path = models.TextField()
def save(self, *args, **kwargs):
# Automatiquement générer le path à partir du parent
if self.path is None:
self.path = "" if self.parent is None else self.parent.path
self.path += f"/{self.user.id}"
super().save(*args, **kwargs)
def get_children(self):
children_id = [
documentaccessright.user_id
for documentaccessright in DocumentAccessRight.models.filter(
parent__contains=f"/{self.user_id}/"
)
}
return children_id
def get_parents(self):
parents_id = self.path.split("/")[1:-1] # 0 is empty, last is self
return parents_id
Cette version donne exactement les mêmes fonctionnalités que la précédente mais l'avantage de fonctionner en une seule requête SQL, et sans besoin de fonctions récursives.
Elle a cependant quelques défauts:
- On stocke le path dans un champ de type
Text, de taille indéfinie (impossible à indexer) ; - On fait des recherches de type
containsqui se traduisent en SQL enLIKE '%foo%', ce qui est très peu performant ; - Si jamais on veut déplacer un élément dans l'arbre (par exemple dire que
Charlydevient le fils direct deBob), il faut modifier lepathtous les fils de l'élément déplacé.
(Note: Concernant ce dernier point, cela ne nous concerne pas dans le use-case de Seald, il n'est donc pas traité dans cet article)
Approche optimisée
(NDLA: à partir de là, il s'agit de ma propre implémentation. Je ne sais pas s'il s'agit d'un pattern classique, ou s'il y a de très mauvaises retombés quelque part, si c'est le cas n'hésitez pas à m'en faire part en commentaire)
L'approche à partir d'un path semble bonne. Cependant, en vue des inconvénients précédemment mentionnées, il est
sûrement possible d'améliorer le modèle. Pour cela, il ne faut plus utiliser un TextField pour stocker le path,
mais une structure plus appropriée.
Pour reprendre l'exemple précédent, les path sont les suivants :
- Alice :
/Alice - Bob :
/Alice/Bob - Charly :
/Alice/Charly - Dylan :
/Alice/Charly/Dylan
PostgreSQL propose un type de champ propre (n'existant ni sur SqlLite / MySQL / MariaDB) : l'Arrays. Ce type de champ est également accessible via l'ORM de Django via l'ArrayField.
Ainsi, le path pourrait être représenté par les tableaux suivants :
- Alice :
[Alice] - Bob :
[Alice, Bob] - Charly :
[Alice, Charly] - Dylan :
[Alice, Charly, Dylan]
Et ainsi, la recherche des enfants d'un élément ne se fait plus par un LIKE %foo%, mais par la vérification
qu'un élément du path est présent. Mieux encore, pour trouver les enfants de Charly, il suffirait de vérifier tous
les éléments dont Charly est présent dans le path, mais on peut encore optimiser la recherche, car on sait que si
Charly est présent dans le path, il sera forcément en 2ème position, il n'est donc pas nécessaire de vérifier tout
le path.
Résultat
L'implémentation de cette version peut se faire ainsi:
from django.contrib.postgres.fields import ArrayField
from django.db import models
class DocumentAccessRight(model.Model):
user = models.ForeignKey("SealdUser", on_delete=models.CASCADE)
document = models.ForeignKey("Document", on_delete=models.CASCADE)
parent = models.ForeignKey(
"DocumentAccessRight",
on_delete=models.CASCADE,
null=True
)
path = ArrayField(models.IntegerField()) # A changer selon le type d'index
def save(self, *args, **kwargs):
# Automatiquement générer le path à partir du parent
if self.path is None:
self.path = [] if self.parent is None else self.parent.path
self.path.append(self.user.id)
super().save(*args, **kwargs)
def get_children(self):
query = {f"path__{len(self.path) - 1}": self.user_id} # Ex: {"path__2": 12}
children_id = [
i
for i in MessageAccess.objects.filter(**query).values("user")
]
return children_id
def get_parents(self):
parents_id = self.path
return parents_id
Cette implementation reprend tous les avantages de la précédente, à la différence que la recherche des enfants d'un noeud se traduit par une comparaison d'égalité sur un élément indexable en base, améliorant considérablement les performances de la requête.
Il reste quand même quelques notes négatives :
- On utilise des tableaux pour stocker TOUT le
path; dans un contexte où un objet serait "profond" dans l'arbre, cela peut avoir un impact sur l'espace de stockage ; - Le déplacement d'un objet dans l'arboressence peut être très complexe et n'est pas du tout géré par l'implémentation.
Cependant, ces deux points sont clairement assumés en vu du contexte de leur utilisation, ce qui n'est pas forcément le cas de tous les use cases.